In an era where healthcare systems become the learning entities, routinely collected healthcare data such as electronic health records (EHR), insurance claims data, and registries open up new research opportunities but also come with unique challenges, which motivate my methodological research. Specifically, my research has two primary focuses:
- developing robust and efficient causal inference methods for comparative effectiveness and safety surveillance studies in the presence of unmeasured and mismeasured confounding, mediation, rare adverse outcomes with many confounders, and privacy concerns
- bridging statistics, computer science and biomedical informatics to promote data-driven healthcare, in areas such as analyzing data corrupted by linkage error and mismatch between the response and predictor, with an application to unsupervised machine translation of medical concepts, high-throughput comparison of medical codes and healthcare utilization, and medical knowledge extraction from massive sources of healthcare data unifying text and billing codes.
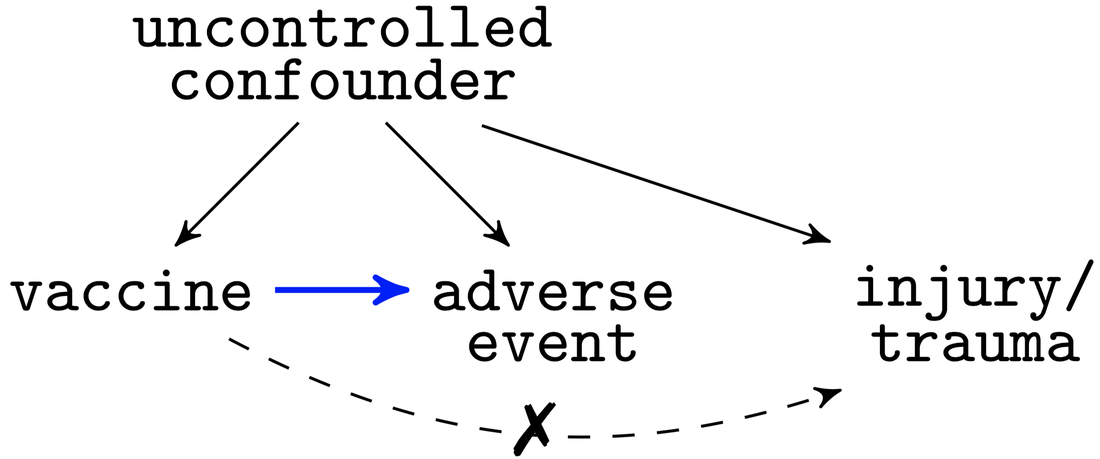
The future does not affect the past: past health outcome is a negative control in air pollution study
|
The negative control, defined as a factor known a priori to follow a null model, is a hidden treasure in causal inference to mitigate confounding bias. Biology experiments often leave out an essential ingredient to create a negative control to ensure that experimental results are valid. In observational studies, negative controls have been used to detect confounding bias. It turns out that one can go beyond bias detection and adjust for confounding bias with multiple negative controls. In Shi et. al. 2020, we develop multiply robust causal inference method to estimate the average treatment effect in the presence of unmeasured confounding leveraging a pair of negative controls. Our estimator exploits the full information in the data to achieve robustness to model misspecification. Negative controls hold promises for causal inference using EHR data as they are widely available due to the extensive medication history and longitudinal structure in EHRs.
|
- Multiply robust causal inference with double negative control adjustment for categorical unmeasured confounding
Shi X, Miao W, Nelson J, and Tchetgen Tchetgen EJ (2020). Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(2):521-540 - A Selective Review of Negative Control Methods in Epidemiology
Shi X, Miao W, and Tchetgen Tchetgen EJ (2021). Current Epidemiology Reports, in press. - Theory for identification and Inference with Synthetic Controls: A Proximal Causal Inference Framework
Shi X, Miao W, Hu M, and Tchetgen Tchetgen EJ. (2021) - An Introduction to Proximal Causal Learning
Tchetgen Tchetgen EJ, Ying A, Cui Y, Shi X, and Miao W. (2021). - Semiparametric proximal causal inference
Cui Y, Pu H, Shi X, Miao W, Tchetgen Tchetgen EJ. (2021) - Proximal Causal Inference for Complex Longitudinal Studies
Ying A, Miao W, Shi X, Tchetgen Tchetgen EJ. (2021) - A Confounding Bridge Approach for Double Negative Control Inference on Causal Effects
Miao W, Shi X, and Tchetgen Tchetgen EJ. (2021).
- Theory for identification and Inference with Synthetic Controls: A Proximal Causal Inference Framework
Shi X, Miao W, Hu M, and Tchetgen Tchetgen EJ. (2021)
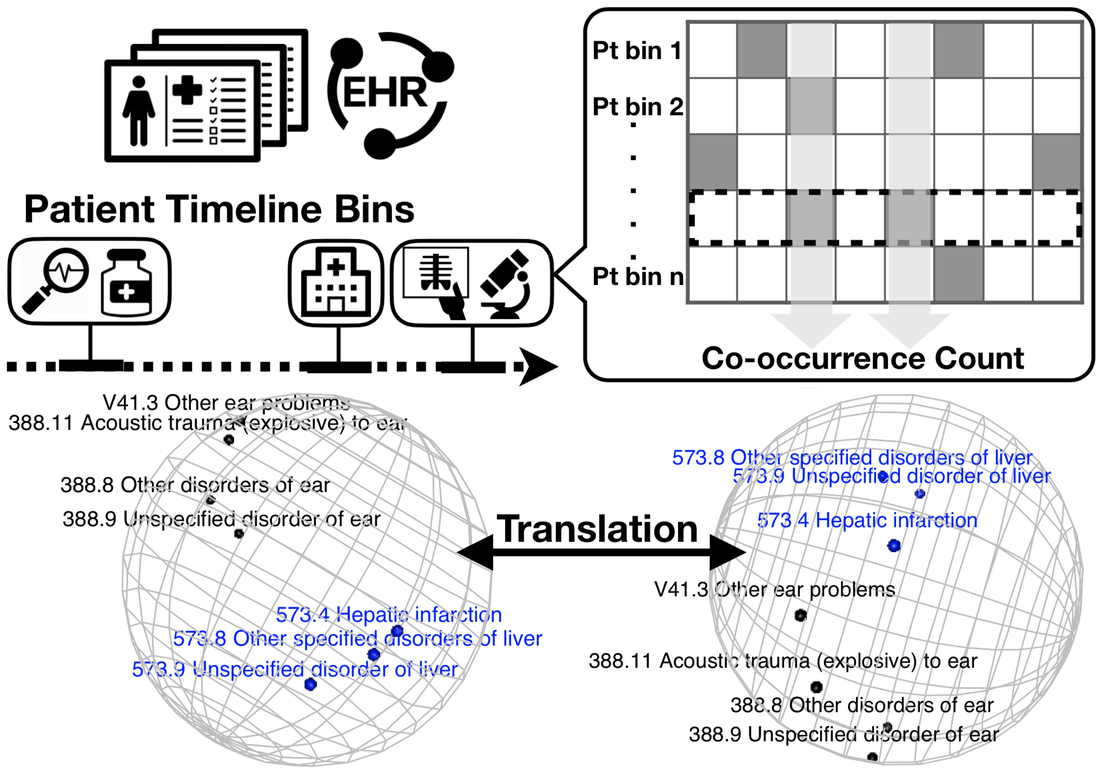
Medical knowledge extraction and ICD code translation
|
Due to the financial incentives and heterogeneity in healthcare systems, different providers may use alternative medical codes to record the same diagnosis or procedure. Inconsistent coding across EHR systems limits the transportability of statistical models.
In Beam et. al. 2020, we generate semantic embedding vectors (SEV) of ICD-9 codes from their co-occurrence patterns in EHRs, using concept embedding algorithms such as word2vec. The directions of the data-driven SEVs encode their relationship and clinical meaning of the codes. Codes with similar concepts are closer to each other on the sphere, which allows translation of codes between systems. |
In Shi et. al. 2020, we turn the code translation problem into a statistical problem of relating two sets of unit-length SEVs trained from two respective healthcare systems. The statistical problem is particularly interesting because the training data is corrupted by a fraction of mismatch in the response-predictor pairs, whereas classical regression analysis tacitly assumes that the response and predictor are correctly linked. We propose the iterative spherical regression mapping method to link the two sets of SEVs, which outperforms conventional machine translation method. We establish theoretical guarantees for estimation and model selection consistency. Our theoretical findings shed light on recent effort in record linkage and common data model for EHR data as we illustrate how estimation error depends on linkage error and how one could correct the mismatch leveraging group information.
- Spherical regression under mismatch corruption with application to automated knowledge translation
Shi X, Li X, and Cai T (2020). Journal of the American Statistical Association: Theory and Methods, in press - Clinical concept embeddings learned from massive sources of multimodal medical data
Beam AL, Kompa B, Fried I, Palmer N, Shi X, Cai T, and Kohane I (2020). Pacific Symposium on Biocomputing (PSB), 25: 295-306 - Phenotype risk scores (PheRS) for pancreatic cancer using time-stamped electronic health record data: Discovery and validation in two large biobanks.
Salvatore M, Beesley L, Fritsche L, Hanauer D, Shi X, Mondul A, Pearce C, Mukherjee B (2020). Journal of Biomedical Informatics, in press. - Patient Recruitment Using Electronic Health Records Under Selection Bias: a Two-phase Sampling Framework
Zhang G, Beesley LJ, Mukherjee B, Shi X. (2020)
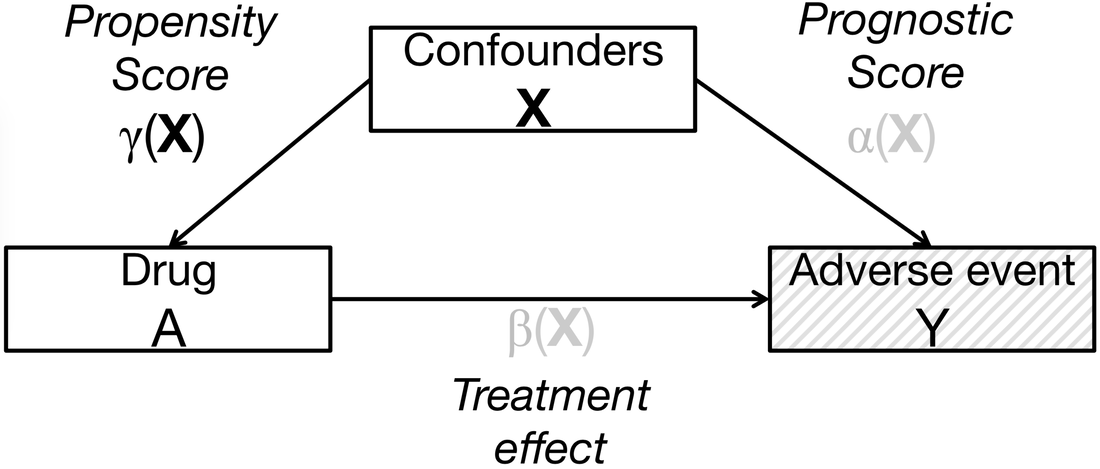
Rare adverse event and high-dimensional covariates necessitates flexible propensity score methods
|
Clinical trials are often too small to systematically detect rare events and may not be generalizable to the population who will ultimately receive the medical products. In contrast, large-scale observational healthcare databases provide rich patient information from a broad population in the real world, facilitating the evaluation of factors associated with both individual benefit and potential harm. For example, the FDA created the Sentinel Initiative, a surveillance network with over 100 million patient lives to monitor the safety of its regulated medical products using EHR databases from numerous data partners across the US. However, in safety surveillance study, the adverse event is often extremely rare. In contrast, given sufficient uptake of the exposure and comparator medication, propensity score methods can provide both sufficient control of confounding and dimension reduction. In Shi et. al. 2020, we characterize a flexible regression on the estimated propensity score method with a computationally efficient variance estimator to infer the causal effect in a select population.
|
- Safety surveillance and the estimation of risk in select populations: flexible methods to control for confounding while targeting marginal comparisons via standardization
Shi X, Wellman R, Heagerty PJ, Nelson JC, and Cook AJ (2020). Statistics in Medicine, 39(4):369-386 - Safety signaling methods for survival outcomes to control for confounding in the Mini-sentinel distributed database
Cook AJ, Wellman RD, Shi X, Izem R, Zhang R, Nguyen M, Tiwari RC, Heckbert SR, Gruber S, and Nelson JC (2018). FDA’s Sentinel Initiative: Project Report - Veridical Causal Inference using Propensity Score Methods for Comparative Effectiveness Research with Medical Claims
Ross R, Shi X, Caram M, Tsao P, Lin P, Bohnert A, Zhang M, Mukherjee B (2020). Health Services and Outcomes Research Methodology, in press. - A Comparison of Parametric Propensity Score-Based Methods for Causal Inference with Multiple Treatments and a Binary Outcome
Yu Y, Zhang M, Shi X, Caram M, Little R, Mukherjee B (2020). Statistics in Medicine, in press.
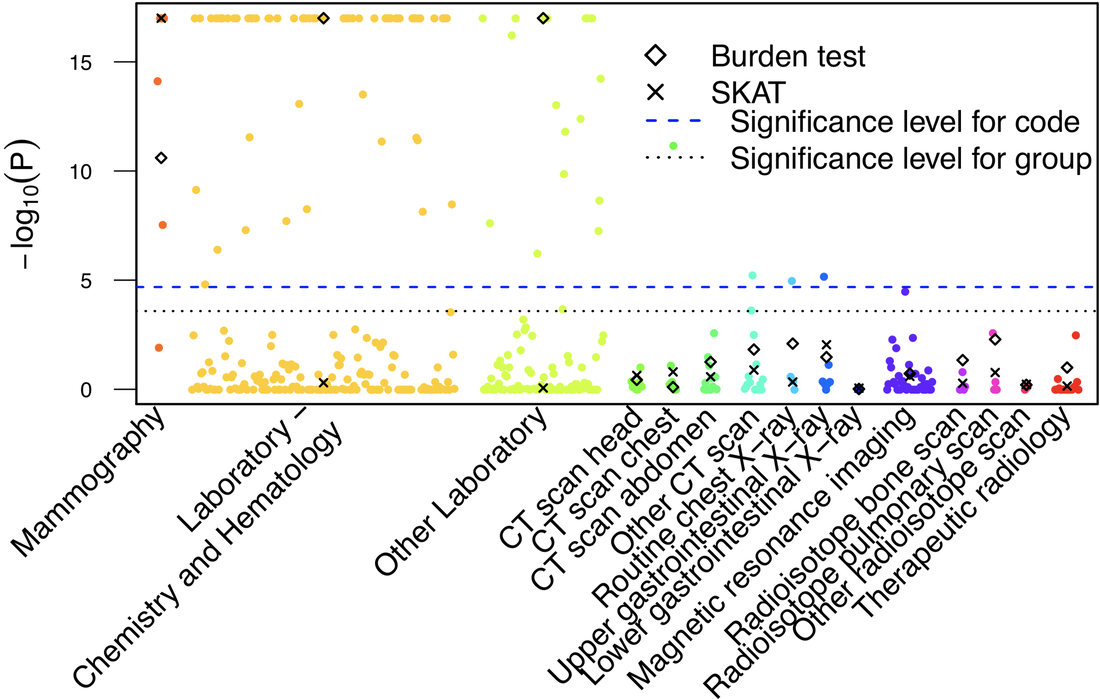
Coding differences and differential healthcare utilization patterns between Henry Ford Health System and Kaiser Permanente
|
Recent federal initiatives are moving from the adoption and collection towards the linkage and integration of EHRs across clinics, hospitals, and healthcare systems. A key challenge to the use of electronically assembled cohorts is the potential for variation in both the choice of specific procedures and coding practices in different healthcare systems and across time. In Shi et. al. 2017, we scan the full spectrum of medical procedure codes to detect differential healthcare utilization patterns and identify data quality issues. Hierarchical structure in terms of medical code grouping and provider-level clustering adds unique complexity to the analysis of EHR data. We adapt groupwise genetic association tests and develop inference method for adaptive shrinkage accounting for potential correlation driven by provider behavior. We ultimately provide interpretable dynamic graphical tools implemented in an interactive web application, which were used to assess the effect of early imaging on downstream healthcare utilization among the elderly with back pain in Jarvik et. al. 2015.
|
- Comparing healthcare utilization patterns via global differences in the endorsement of current procedural terminology codes [Distinguished Oral Presentation Award, WNAR 2015]
Shi X, Pashova H, and Heagerty PJ (2017). Annals of Applied Statistics, 11(3):1349-1374 - Association of early imaging for back pain with clinical outcomes in older adults
Jarvik, JG, Gold, LS, Comstock, BA, Heagerty, PJ, Rundell, SD, Turner, JA, Avins, AL, Bauer, Z, Bresnahan, BW, Friedly, JL, James, K, Kessler, L, Nedeljkovic, SS, Nerenz, DR, Shi X, Sullivan, SD, Chan, L, Schwalb, JM, and Deyo, RA (2015). Journal of the American Medical Association, 313(11):1143-1153
The Seattle Times: "Minimally invasive surgery a safe option for major liver cases, UW study finds", by JoNel Aleccia
|
I collaborate with researchers in surgery on multi-site comparative effectiveness studies. For example, in Thornblade et al. 2017a, a retrospective study of patients undergoing hepatectomies at 67 hospitals was conducted to assess the comparative effectiveness between minimally invasive surgery (such as laparoscopy and robotic surgery) and conventional open surgery. This is the largest multi-institution study in this field, and we demonstrated that minimally invasive surgery is a safe option for major liver operations. Our finding was featured in the Seattle Times. Thornblade et al. 2017b is a prospective study of patients undergoing colorectal surgery in Washington State looking at association between immunonutrition prior to elective colorectal surgery and serious adverse events. Because of differences in surgeon and hospital practices, there was concern for variation across hospitals in both the receipt of immunonutrition and the outcomes. To account for unmeasured differences, I proposed to perform matching within hospital and found that immunonutrition was associated with decreased postoperative length of stay.
|
- The comparative effectiveness of minimally invasive surgery and conventional approaches to major or challenging hepatectomies [covered by the Seattle Times]
Thornblade LW, Shi X, Ruiz A, Flum DR, and Park JO (2017a). Journal of the American College of Surgeons, 224(5):851-861 - Preoperative immunonutrition and elective colorectal resection outcomes
Thornblade LW, Varghese TK, Shi X, Johnson EK, Bastawrous A, Billingham RP, Thirlby R, Fichera A, and Flum DR (2017b). Diseases of Colon and Rectum, 60(1):68-75